The warehouses are as follows: snailyp/ip-checker: 一个基于clash api调用ip-api,scamalytics,ping0等网站获取ip纯净度的项目 (github.com)
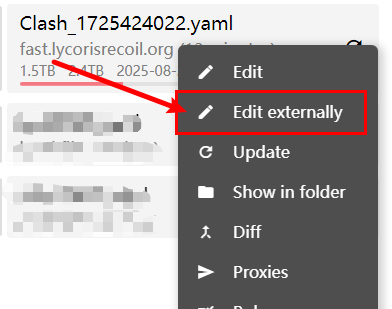
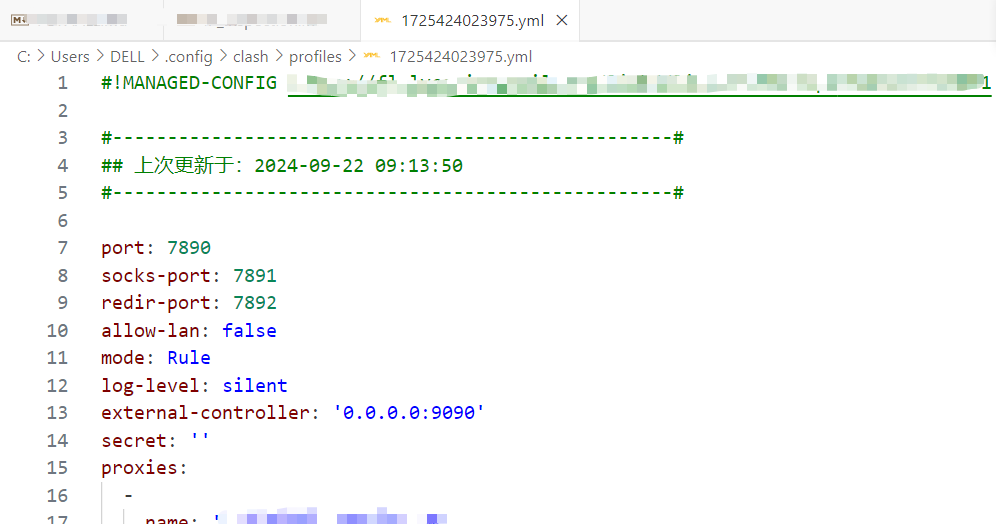
Download-->open folder-->pip install requirements.txt file dependencies-->find yaml/yml in clash that you want to test-->Edit externally-->find the corresponding path-->copy file to download folder-->rename to clash. yml-->Run clash_config.py file-->Get new_clash.yml-->Import New file-->There is a config.json file in the folder-->Modify it (no need to modify it if it is already aligned with your own config.yaml file in clash. secret, other defaults)-->python main.py
1{2"external_controller": "http://127.0.0.1:9097", //改成自己的clash外部控制地址3"secret": "", //clashapi秘钥,没有秘钥不用管4"select_proxy_group": "GLOBAL", //默认,不用管5"port_start": 42000, //clash开放起始端口号6"max_threads": 20 //线程池中最大线程数7}
(To be honest, I didn't even succeed myself, my python main.py kept reporting an error, and after I tinkered with the code and clash for an hour, I realized that it was a problem with my version, so I stopped trying, I didn't want to uninstall and download the normal version, if the version is correct it should be fine, and it seems that there is nothing wrong with the Clash Verge Re, so try to test it)
Batch test with py script (tried it and found that ping0.cc blocked it, hey, I don't know if the above kind of way still works, I guess it doesn't work either, I see that there is something wrong with the api interface management):
x1import requests2import json3import csv4import os5import time6from bs4 import BeautifulSoup7# Constants9IP_FILE = 'ips.txt'10OUTPUT_FILE = 'ip_report.csv'11HEADERS = {12"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"13}14SCAMALYTICS_URL = "https://scamalytics.com/ip/"15PING0_URL = "https://ping0.cc/ip/"16# Function to fetch IP details from ip-api.com18def fetch_ip_details(ip):19url = f"http://ip-api.com/json/{ip}"20try:21response = requests.get(url, timeout=10)22data = response.json()23if data['status'] == 'success':24return {25'IP': ip,26'Organization': data.get('org', ''),27'City': data.get('city', ''),28'Region': data.get('regionName', ''),29'ZIP': data.get('zip', ''),30'Country': data.get('country', ''),31'Longitude': data.get('lon', ''),32'Latitude': data.get('lat', ''),33'ISP': data.get('isp', ''),34'AS': data.get('as', '')35}36else:37print(f"[ip-api.com] Failed to fetch details for IP: {ip}")38return {'IP': ip, 'Error': 'Failed to fetch details'}39except Exception as e:40print(f"[ip-api.com] Error fetching details for IP {ip}: {e}")41return {'IP': ip, 'Error': str(e)}42# Function to fetch risk data from scamalytics.com44def fetch_scamalytics(ip):45url = f"{SCAMALYTICS_URL}{ip}"46try:47response = requests.get(url, headers=HEADERS, timeout=10)48if response.status_code == 200:49# Simple regex parsing50score = None51risk = None52try:53json_data = json.loads(response.text)54score = json_data.get('score', '')55risk = json_data.get('risk', '')56except:57# Fallback to HTML parsing if JSON fails58soup = BeautifulSoup(response.text, 'lxml')59score_tag = soup.find('span', {'id': 'score'})60risk_tag = soup.find('span', {'id': 'risk'})61score = score_tag.text.strip() if score_tag else ''62risk = risk_tag.text.strip() if risk_tag else ''63return {64'Scamalytics_Score': score,65'Scamalytics_Risk': risk66}67else:68print(f"[Scamalytics] Failed to fetch risk for IP: {ip}")69return {'Scamalytics_Score': 'N/A', 'Scamalytics_Risk': 'N/A'}70except Exception as e:71print(f"[Scamalytics] Error fetching risk for IP {ip}: {e}")72return {'Scamalytics_Score': 'Error', 'Scamalytics_Risk': str(e)}73# Function to fetch risk data from ping0.cc75def fetch_ping0(ip):76try:77# Initial request to get window.x value from the HTML78response = requests.get(f"{PING0_URL}{ip}", headers=HEADERS, timeout=10)79if response.status_code != 200:80print(f"[Ping0.cc] Failed initial request for IP: {ip}")81return {'Ping0_RiskValue': 'N/A', 'Ping0_IPType': 'N/A', 'Ping0_NativeIP': 'N/A'}82soup = BeautifulSoup(response.text, 'lxml')84script_tags = soup.find_all('script')85window_x = None86for script in script_tags:87if 'window.x' in script.text:88# Extract window.x value89try:90window_x = script.text.split("window.x = '")[1].split("';")[0]91break92except:93continue94if not window_x:95print(f"[Ping0.cc] Failed to parse window.x for IP: {ip}")96return {'Ping0_RiskValue': 'N/A', 'Ping0_IPType': 'N/A', 'Ping0_NativeIP': 'N/A'}97# Second request with the jskey cookie99cookies = {'jskey': window_x}100response_final = requests.get(f"{PING0_URL}{ip}", headers=HEADERS, cookies=cookies, timeout=10)101if response_final.status_code != 200:102print(f"[Ping0.cc] Failed final request for IP: {ip}")103return {'Ping0_RiskValue': 'N/A', 'Ping0_IPType': 'N/A', 'Ping0_NativeIP': 'N/A'}104soup_final = BeautifulSoup(response_final.text, 'lxml')106# Extract data using XPath-like selectors107# Since BeautifulSoup doesn't support XPath, use find/find_all with class or id108# Modify these selectors based on the actual HTML structure of ping0.cc109try:110risk_value = soup_final.select_one('div:nth-of-type(9) > div:nth-of-type(2) > span').text.strip()111except:112risk_value = 'N/A'113try:114ip_type = soup_final.select_one('div:nth-of-type(8) > div:nth-of-type(2) > span').text.strip()115except:116ip_type = 'N/A'117try:118native_ip = soup_final.select_one('div:nth-of-type(11) > div:nth-of-type(2) > span').text.strip()119except:120native_ip = 'N/A'121return {123'Ping0_RiskValue': risk_value,124'Ping0_IPType': ip_type,125'Ping0_NativeIP': native_ip126}127except Exception as e:129print(f"[Ping0.cc] Error fetching Ping0 data for IP {ip}: {e}")130return {'Ping0_RiskValue': 'Error', 'Ping0_IPType': 'Error', 'Ping0_NativeIP': str(e)}131# Function to process a single IP133def process_ip(ip):134print(f"Processing IP: {ip}")135ip_details = fetch_ip_details(ip)136if 'Error' in ip_details:137return ip_details138scamalytics = fetch_scamalytics(ip)140ping0 = fetch_ping0(ip)141# Merge all data into a single dictionary143combined_data = {**ip_details, **scamalytics, **ping0}144return combined_data145# Function to read IPs from file147def read_ips(file_path):148if not os.path.exists(file_path):149print(f"IP file '{file_path}' not found.")150return []151with open(file_path, 'r') as f:152ips = [line.strip() for line in f if line.strip()]153return ips154# Function to write results to CSV156def write_to_csv(data, file_path):157if not data:158print("No data to write.")159return160# Get headers from the first item's keys161headers = data[0].keys()162with open(file_path, 'w', newline='', encoding='utf-8') as f:163writer = csv.DictWriter(f, fieldnames=headers)164writer.writeheader()165for row in data:166writer.writerow(row)167print(f"Results written to {file_path}")168def main():170ips = read_ips(IP_FILE)171if not ips:172print("No IPs to process.")173return174results = []176for ip in ips:177result = process_ip(ip)178results.append(result)179# Optional: Sleep to respect API rate limits180time.sleep(1) # Adjust as needed181write_to_csv(results, OUTPUT_FILE)183if __name__ == "__main__":185main()186
<OVER~>